


Table of contents
- Motivation
- Thoughts on ELT and ETL
- What's dbt
- Setup
- dbt on mac
- vs-code setup for dbt
- CLI components
- dbt init
- .dbt where the secret being stored
- project.yml file
- Concepts of materialization
- Materialization in dbt
- dbt source
- dbt seeds
- dbt docs
- dbt snapshot
- What's SCD type 2?
- define snapshot
- snapshot's configuration
- dbt test
- test overviews in dbt
- Generic tests
- Summary
- Reference
Motivation
What's behind the idea of dbt? why is it getting popularity in the world of data engineering and data analytics? Let's talk about the problems we are facing at the moment as DE:
The amount of analytics SQL code we need to write is really high and variant since business requirement keeps changing. Then you lost track of it!
Lots of testing codes you need to write and need to automate the checking as well.
Documentation is not living with the code, which makes it harder to look at
dbt is designed to solve this problem and let DA (or the fancy new job title analytics engineer) work like a software engineer by adapting their work flows.
Thoughts on ELT and ETL
ETL is the data engineering paradigm that
extract the data from various sources (databases, APIs)
transform it outside with distributed computing framework such as hadoop or spark
load into data warehouse
While the ETL paradigm goes way back to SSIS in MS SQL Server, the concept of ELT is relatively new but really popular.
SSIS was released in 2005 but the concept of ETL goes way back. And Apache Hadoop is released in 2006.
The reason why we use the ETL paradigm is that the database we have back in the day is single node architecture so it doesn't have enough computing power to do the transformation inside the database. Therefore, we extract it from the database and use a computing framework to do it. Finally, we load it into the database (data warehouse).
Now, since the destination database like BigQuery, it is both a distributed storage and a monster computing engine as illustrated in the figure below
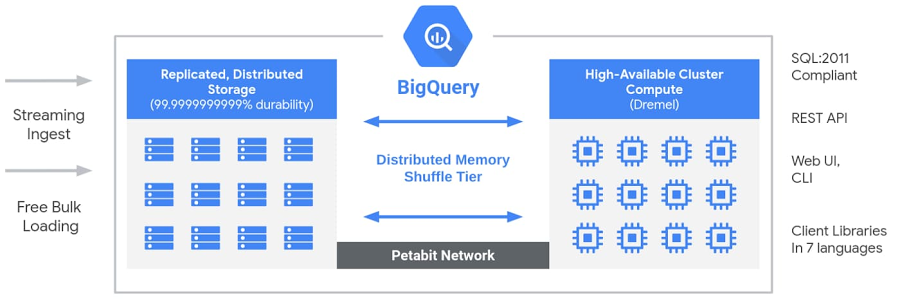
It means that we could do the computing inside our destination data warehouse, which is closer to the end consumers and BI teams. The dbt fits in the picture of ELT and it provides other values such as software engineering best practice.
The ELT paradigm has the pro that the business transformation logics is living closer to the BI team compared with ETL counterpart.
To summarize
| - | ETL | ELT |
| Description | data integration process that involves extracting data from multiple sources, transforming it into a structured format, and loading it into a target system. | extracting data from multiple sources, loading it into a target system, and then transforming it into a structured format. |
| History | The transformation has been done outside of the database due to the limitation of single-node computing inside the database. | Thanks to the data warehouse (big query, redshift and snowflake) It has great scalability. |
| Application | data is transformed outside database. This approach can be useful when dealing with large amounts of data or when transforming data into complex, structured formats. | data is loaded into a target system before being transformed. This approach can be useful when dealing with simple transformations or when working with target systems that are optimized for data processing. |
Now we understand the key difference between ETL and ELT and its history of it. Now, we can dive into the world of dbt!
What's dbt
dbt is the new hot tool for the "transformation" of ETL or ELT.


It is bringing software engineering best practices into analytics and it saves lots of boilerplate codes, and ad-hoc for you.
Some SQL tests you write for your company are great but the truth is that many companies need the same tests. There must be someone out there have done all of the SQL tested and implemented it for you.
It is the new way of doing SQL.
Setup
dbt labs officially support the following database
big query
postgres
redshift
snowflake
But other community developers develop and maintain other database such as dbt-mysql.
To be honest, the officially maintained ones are more up to date with less issues. I suggest use
dbtfor officially supported database platform to minimize the troubles you will bump into
dbt on mac
Just set it up as any other package, create a virtual environment and install
# create .venv for you python virtual env
python -m venv .venv
# activate it, depends on the scripting lang you use (zsh, fish)
source .venv/bin/activate
# now you should in
(.venv)
# install
pip install dbt-postgres && dbt install dbt-core
Install dbt-posrgres will install the dbt-core for you which is the core component of dbt.
Now, you can check
dbt --version
It should give you
Core:
- installed: 1.5.1
- latest: 1.5.1 - Up to date!
Plugins:
- postgres: 1.5.1 - Up to date!
vs-code setup for dbt
As for learning dbt, you just need to know the following scripting (some basic is fine)
SQL, need to be really good at it
jinja template (template engining for python, used by dbt)
yaml
To better use dbt, install those extensions
some extensions are useful:
dbt power user, useful
jinja, must
CLI components
Let's summarize the most important part of the dbt command
| Command | Description |
dbt init | Initializes a new dbt project |
dbt source | Configures the sources where the data will come from. used for tables that just got loaded into |
dbt seed | Loads the raw data into the source tables. Used to define external tables, or relatively quasi-static data |
dbt test | Runs tests on the data to ensure it's clean and consistent. built-in or third-party packages to test your SQL. such as null checking, enum checking, and even audit package |
dbt snapshot | Creates incremental models from the source data, only implementing SCD 2. |
dbt docs | Generates documentation for the models |
dbt init
# create a directory called "project-name" in your working directory
dbt init <project-name>
cd <project-name>
then you will find out something like this
.
├── README.md
├── analyses
├── dbt_packages
├── dbt_project.yml
├── logs
├── macros
├── models
├── seeds
├── snapshots
├── target
└── tests
10 directories, 2 files
The functionality of each directory is summarized here
| Directory | Description |
| analyses | Analytical SQL queries that combine models |
| dbt_packages | Packages installed with dbt, such as dbt-utils |
| dbt_project.yml | Configuration file for a dbt project, IMPORTANT |
| logs | Logs from dbt runs. usually don't care. |
| macros | Reusable SQL code snippets, useful for customized settings |
| models | SQL code that defines data models, is IMPORTANT! |
| seeds | Raw data that is loaded into the source tables |
| snapshots | Incremental models created from the source data |
| target | Compiled SQL code and other artifacts |
| tests | SQL code that tests models for correctness |
.dbt where the secret being stored
After you set up your dbt project, you should build up a database connection
cd ~
cd .dbt
You should see a profiles.yml file that contains all your database connections for your current project:
project_name:
outputs:
dev:
type: postgres
threads: 1
host: [host]
port: 5432
user: [dev_username]
pass: [dev_password]
dbname: postgres
schema: raw
prod:
type: postgres
threads: [1 or more]
host: [host]
port: [port]
user: [prod_username]
pass: [prod_password]
dbname: [dbname]
schema: [prod_schema]
target: dev
You can input ur credentials here
project.yml file
Let's go back to your dbt project, and check out the configuration
# Name your project! Project names should contain only lowercase characters
# and underscores. A good package name should reflect your organization's
# name or the intended use of these models
name: 'project_name'
version: '1.0.0'
config-version: 2
# This setting configures which "profile" dbt uses for this project.
profile: 'dbt_ads'
# These configurations specify where dbt should look for different types of files.
# The `model-paths` config, for example, states that models in this project can be
# found in the "models/" directory. You probably won't need to change these!
model-paths: ["models"]
analysis-paths: ["analyses"]
test-paths: ["tests"]
seed-paths: ["seeds"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]
clean-targets: # directories to be removed by `dbt clean`
- "target"
- "dbt_packages"
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the `{{ config(...) }}` macro.
models:
dbt_ads:
# 在dbt_ads文件夹下的所有文件都会被视为view
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
It is a configuration that list things up. The most crucial part is the last bit
models:
dbt_ads:
# 在dbt_ads文件夹下的所有文件都会被视为view
# Config indicated by + and applies to all files under models/example/
example:
+materialized: view
It touches upon the concept of materialization in database.
Concepts of materialization
In the SQL world, materialization refers to the process of creating a physical table or view in a database from the results of a SQL query. Materialization is used to improve query performance by storing the results of a query in a table or view, which can then be accessed more quickly than re-executing the query every time it is needed.
Note
The initiative behind materialization is the trade-off between time and space. (remind u of leetcode again huh)
Materialization can be done in a variety of ways, depending on the database system and the type of query being executed. Common techniques include:
Creating a temporary table to store the query results
Creating a materialized view, which is a precomputed table that is automatically updated when the underlying data changes
Creating a permanent table to store the query results
Materialization can be an effective way to improve query performance, especially for complex queries that involve large amounts of data. However, it can also be resource-intensive, especially for queries that are executed frequently or involve large amounts of data. As with any performance optimization, it is important to carefully evaluate the trade-offs and test the impact of materialization on query performance and resource usage.
Materialization in dbt
In dbt, it is similar and defined as
| - | View | Table | Incremental Tables | Ephemeral Tables |
| Use it | you want a lightweight representation | you read from this model repeatedly | fact tables; appends to tables | you merely want an alias to your date |
| Don't use it | you read from the same model several times | building single-use models; your model is populated incrementally | you want to update historical records | you read from the same model several times |
Refresh the concept of materialization
Then, if you go back to your yaml file
# file structure for the model/
.
├── dim
│ ├── dim_hosts_cleansed.sql
│ └── dim_listings_cleansed.sql
└── src
├── src_hosts.sql
├── src_listings.sql
└── src_reviews.sql
# yaml file
name: 'dbtlearn'
version: '1.0.0'
config-version: 2
models:
project:
+materialized: view
dim:
+materialized: table
The precedence follows the rule:
The more indentation you have, the later the rule applied
For example, in the file above,
models:
# all files under this dbt "project" folder will be view
project:
+materialized: view
# all files under project/dim will be table
dim:
+materialized: table # 设置dim/内的默认materialized方法为 table
If we word in properly, the materialization in this dbt project became,
All sql files in
project/will be generated as view, except for files in the./project/dim
dbt source
The concept of the source in dbt's project is usually the data just get ingested into the data warehouse.
By default, the source lives in the models table,
models
├── dim
├── fct
├── sources.yml
└── src
├── src_authors.sql
├── src_campaigns.sql
├── src_commerce_users.sql
└── src_hashtags.sql
4 directories, 5 files
You could configure your source.yml file to,
define jinja template for your database table
define freshness checking
An example source.yml file works like this
version: 2
sources:
- name: airbnb
schema: raw
tables:
- name: listings
identifier: raw_listings
- name: hosts
identifier: raw_hosts
- name: reviews
identifier: raw_reviews
loaded_at_field: date
freshness:
# if no data inserted to reviews table within 1 hour, give warning
# if no data inserted to reviews table within 24 hours, give error
warn_after: {count: 1, period: hour}
error_after: {count: 24, period: hour}
You can name it whatever you want for defining the sources, just put down
sources:then you are good to go
You can check the freshness by
dbt source freshness
dbt seeds
The concept of seeds in dbt is for static table (some table never going to change) like countries table illustrated here.
| country_code | country_name |
| CA | Canada |
| CN | China |
To do it, just write a script in project/seeds and run
dbt seed
Note:
The
dbt seedis not designed to handle large dataset. It is designed to load smaller and static dataset.
dbt docs
dbt let you build your documentation with the following commands
# build the doc
dbt docs generate
# run it up at port 8080
dbt docs serve
# run it at a specified port
dbt docs serve --port 8082
dbt snapshot
The concept of dbt snapshot is to handle slowly changing dimension (SCD) type 2.
In this section:
understand scd type 2
understand how
dbthandles type-2 slowly changing dimensionsunderstand snapshot strategies
learn how to create snapshots on top of our listings and hosts models
What's SCD type 2?
Let's consider a table with name and address
| id | name | |
| 1 | Adam | adam.airbnb@gmail.com |
| 2 | Bob | bobs.new.address@gmail.com |
Type 2 slowly changing dimensions means that how to handle historical data. Type 2 is to keep all the historical data and the way to track it is to have two extra columns: valid from and valid to.
valid_from: the date that the data is validvalid_to: the date the data is no longer valid. Ifnull, it means it's still valid.
| id | name | dbt_valid_from | dbt_valid_to | |
| 1 | Adam | adam.airbnb@gmail.com | 2022-01-01 00:00:00 | null |
| 2 | Bob | bob.airbnb@gmail.com | 2022-01-01 00:00:00 | 2022-03-01 12:53:20 |
| 3 | Bob | bobs.new.address@gmail.com | 2022-01-01 00:00:00 | null |
Instead of writing some codes to generate those columns, dbt handle those codes for you behind the scene.
define snapshot
Snapshots lives in the snapshots folder. Define a snapshot in the dbtproject/snapshots/ folder uses sql and jinja templates.
-- start of jinja template
{% snapshot scd_authors %}
-- set up config for this snapshot
{{
config(
target_schema='snapshots',
unique_key='id',
strategy='timestamp',
updated_at='ingested_date',
)
}}
-- by default, this is the conventation
select * FROM {{ source('postgres', "tiktok_authors") }}
{% endsnapshot %}
snapshot's configuration
For the comprehensive configuration, please refer official docs here.
The most important figure it the strategy. It has two options:
timestamp: A unique key and a updated_at field is defined on the source model. There columns are used for determining changes.- It relies heavily on
ingest_bycolumn.
- It relies heavily on
check: any change in a set of columns (or all columns) will be picked up as an update.
dbt test
Overview:
Understand how tests can be defined
Configure built-in generic tests
Create your own singular tests
test overviews in dbt
There are two types of tests in dbt: singular and generic.
flowchart TD
a(tests_in_dbt) --> b(singular) & c(generic)
c --> d(built-in) & e("custom")
d --> f("unique") & g("null") & h("accepted_value") & i("relationships")
Generic tests
As for generic tests, you can:
use the
built-inoneswrite your own generic tests or import tests from dbt package
As for built-in tests, just define a yaml file. The convention is called schema.yml
Summary
In this summary, we covered the following topics
why dbt?
set up with dbt
some basic CLI of dbt